
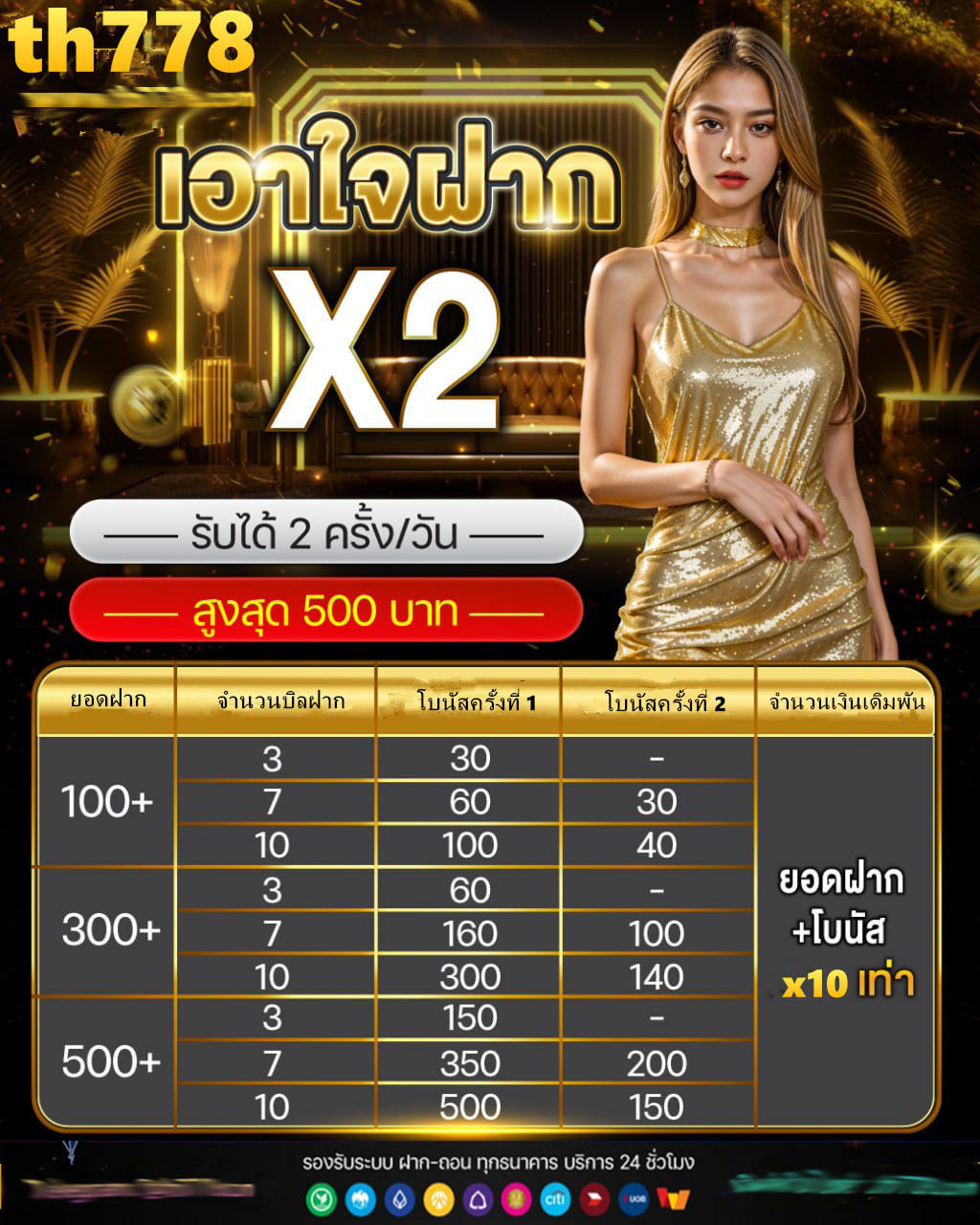



unsloth multi gpu
฿10.00
unsloth multi gpu unsloth pypi Unsloth – Training agents with reinforcement learning Chitra The Summit is hosted by Berkeley RDI, a multi-disciplinary campus
pungpung slot Unsloth makes Gemma 3 finetuning faster, use 60% less VRAM, and enables 6x longer than environments with Flash Attention 2 on a 48GB
unsloth installation Unsloth provides 6x longer context length for Llama training On 1xA100 80GB GPU, Llama with Unsloth can fit 48K total tokens (
unsloth install Plus multiple improvements to tool calling Scout fits in a 24GB VRAM GPU for fast inference at ~20 tokenssec Maverick fits
Add to wish list- SKU:643924251
- Category:Game
- Tags:unsloth multi gpu
Product description
unsloth multi gpuunsloth multi gpu ✅ Best way to fine-tune with Multi-GPU? Unsloth only supports single unsloth multi gpu,Unsloth – Training agents with reinforcement learning Chitra The Summit is hosted by Berkeley RDI, a multi-disciplinary campus&emspIn this post, we introduce SWIFT, a robust alternative to Unsloth that enables efficient multi-GPU training for fine-tuning Llama



